

Migrating Data Across Kafka Clusters in Kubernetes
An overview of K8s' Strimzi Operator and how to manage data migrations with MirrorMaker 2


There are a handful of tasks that do a great job of instilling dread in a software engineer. You know the feeling - you're not quite sure how to approach it, or what the potential ramifications could be should the task implementation go wrong. Nothing does a better job of dredging up those feelings than Kafka migrations.
In the first Technical Tuesdays post, I'll discuss how to migrate Kafka topics as well as consumer group offsets from a source cluster to a destination cluster using Strimzi Operator and MirrorMaker 2 on Kubernetes.
Generally, a simple producer-consumer cutover process is more than enough for most Kafka migration use cases, but this approach results in delayed message delivery during the cutover. There are some cases where delays are not an option during the cutover. This is where MirrorMaker 2 comes in - MirrorMaker 2 allows for a seamless migration and cutover process that mitigates the downtime risk.
Let's dive in.
What’s the goal?
The goal is to migrate two topics from one cluster to another. A migration of Kafka topics across clusters is a unique challenge in that there are a lot of moving parts involved. For example, in a simple migration scenario we have to consider the migration of the following:
Topics
Consumer group offsets
The following diagram represents a high-level migration of 2 simple topics from an "origin cluster" to a "destination cluster":
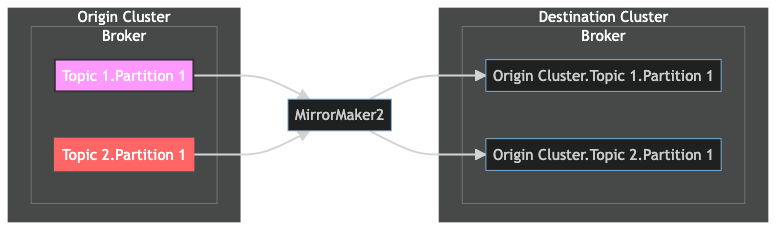
Using the above diagram as an example, we'll leverage MirrorMaker 2 to sync the 2 topics and their consumer group offsets.
The rest of the post will explore the "MirrorMaker2" component in the middle of the diagram.
Time Out: What's MirrorMaker?
MirrorMaker 2 (MM2) is a tool provided by Apache Kafka for copying data between two Kafka clusters. MM2 supports functionality for replicating "topics, topic configurations, consumer groups and their offsets, and ACLs". MM2 leverages Kafka Connectors to consume data from a source cluster, and produce that data to the destination cluster.
From here on forth, I'll refer to MM2's replication functionality as mirroring. Apache makes that distinction because replication is a core feature set of Kafka, and the "mirroring" term is a way to distinguish that data is being replicated from one Kafka cluster to the other.
You can read more about MirrorMaker and its implementation at the official apache/kafka repo.
Let's set up MirrorMaker 2
This implementation will leverage Strimzi Operator's MM2 configuration in order to allow for data mirroring between 2 clusters. We'll set up an active/passive MM2 mirror, which will allow for syncing data in a uni-directional fashion. It's also possible to set up an active/active mirror, but that's outside of the scope of this post.
Strimzi Operator allows for deploying Kafka infrastructure via Kubernetes. It also allows for deploying other Kafka-related technologies, such as Kafka Connect, MM2, and Kafka Bridge. Strimzi Operator provides Custom Resource Definitions (CRDs) that make it easier to manage and operate Kafka infrastructure as a first-class resource in Kubernetes. In order to get started with Strimzi Operator in minikube (or any K8S cluster), you can get started with the Strimzi Operator's bootstrap template. An example implementation is available at irmiller22/mirrormaker2-poc.
Now, on to the MM2 configuration.
The MM2 configuration is based off of the KafkaMirrorMaker2 spec of the Strimzi Kafka Operator API, and is implemented in Kubernetes as a KafkaMirrorMaker2 CRD. Looking at the spec, there are a couple of key properties:
connectCluster
clusters
mirrors
Let's explore these by looking at an example YAML KafkaMirrorMaker2 resource configuration, and we'll discuss the key properties further.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: kafka-mirror
spec:
version: 3.4.0
replicas: 1
connectCluster: "destination-cluster"
clusters:
- alias: "origin-cluster"
bootstrapServers: origin-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: origin-cluster-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: admin-user-1
certificate: user.crt
key: user.key
config:
config.storage.replication.factor: -1
offset.storage.replication.factor: -1
status.storage.replication.factor: -1
- alias: "destination-cluster"
bootstrapServers: destination-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: destination-cluster-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: admin-user-2
certificate: user.crt
key: user.key
config:
config.storage.replication.factor: 1
config.storage.topic: mirrormaker2-cluster-configs
offset.storage.replication.factor: 1
offset.storage.topic: mirrormaker2-cluster-offsets
status.storage.replication.factor: 1
status.storage.topic: mirrormaker2-cluster-status
mirrors:
- sourceCluster: "origin-cluster"
targetCluster: "destination-cluster"
sourceConnector:
tasksMax: 3
config:
replication.factor: 3
offset-syncs.topic.replication.factor: 1
sync.topic.acls.enabled: "false"
replication.policy.separator: "."
replication.policy.class: "io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy"
refresh.topics.interval.seconds: 60
heartbeatConnector:
config:
heartbeats.topic.replication.factor: 3
checkpointConnector:
config:
checkpoints.topic.replication.factor: 3
sync.group.offsets.enabled: true
refresh.groups.interval.seconds: 60
topicsPattern: ".*"
groupsPattern: ".*"
logging:
type: inline
loggers:
connect.root.logger.level: "INFO"
readinessProbe:
initialDelaySeconds: 45
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 45
timeoutSeconds: 5Let's break each key property down step by step.
The connectCluster property should be set to the alias that's specified for the destination cluster. In other words, it should be defined as the cluster that data is being mirrored to. In the example above, connectCluster would be set to destination-cluster:
spec:
...
connectCluster: "destination-cluster"
...
The clusters property represents a list of Kafka clusters that will be used in the replication process, one of which is the source cluster and one of which is the destination cluster. The KafkaMirrorMaker2ClusterSpec describes the properties that make up the spec. Let's look at the the spec specified in the example above:
spec:
...
clusters:
- alias: "origin-cluster"
bootstrapServers: origin-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: origin-cluster-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: admin-user-1
certificate: user.crt
key: user.key
config:
config.storage.replication.factor: -1
offset.storage.replication.factor: -1
status.storage.replication.factor: -1
- alias: "destination-cluster"
bootstrapServers: destination-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: destination-cluster-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: admin-user-2
certificate: user.crt
key: user.key
config:
config.storage.replication.factor: 1
config.storage.topic: mirrormaker2-cluster-configs
offset.storage.replication.factor: 1
offset.storage.topic: mirrormaker2-cluster-offsets
status.storage.replication.factor: 1
status.storage.topic: mirrormaker2-cluster-status
For each cluster definition, there are several keys that need to be defined:
aliasbootstrapServerstls(only if TLS is enabled)authentication(only if authentication is required for the respective cluster)config(only if there are additional Kafka configs that are required)
These properties will look familiar to you if you've worked with Kafka before. These keys represent the configuration details needed in order for MirrorMaker2 to connect to each cluster.
The mirrors property represents the KakfaMirrorMaker2 mirroring configuration, and is a list of mirroring configurations. In other words, this property specifies how the data should flow in between the clusters configured in the clusters property. The KafkaMirrorMaker2MirrorSpec describes the properties that make up the spec. Let's look at the mirrors property that we defined earlier:
spec:
...
mirrors:
- sourceCluster: "origin-cluster"
targetCluster: "destination-cluster"
sourceConnector:
tasksMax: 3
config:
replication.factor: 3
offset-syncs.topic.replication.factor: 1
sync.topic.acls.enabled: "false"
replication.policy.separator: "."
replication.policy.class: "io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy"
refresh.topics.interval.seconds: 60
heartbeatConnector:
config:
heartbeats.topic.replication.factor: 3
checkpointConnector:
config:
checkpoints.topic.replication.factor: 3
sync.group.offsets.enabled: true
refresh.groups.interval.seconds: 60
topicsPattern: ".*"
groupsPattern: ".*"
...
There are a couple of key properties for each mirroring configuration:
sourceClustertargetClustersourceConnectorheartbeatConnectorcheckpointConnectortopicsPatterngroupsPattern
The sourceCluster and targetCluster properties are self-explanatory, but let's dig into the other properties one-by-one.
The sourceConnector represents the configuration for the Kafka Connector belonging to the source cluster. The source cluster's Kafka Connector is responsible for replicating topics, consumer groups, ACLs, and any other cluster-specific configurations from the source cluster to the destination cluster. Additionally, it's also responsible for emitting messages to the offset-syncs topic that keeps track of the latest consumer group offsets for the respective topics. In the configuration example above, the sourceConnector configuration has the following properties:
spec:
...
mirrors:
- ...
sourceConnector:
tasksMax: 3
config:
replication.factor: 3
offset-syncs.topic.replication.factor: 1
sync.topic.acls.enabled: "false"
replication.policy.separator: "."
replication.policy.class: "io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy"
refresh.topics.interval.seconds: 60
...
For the above configuration, the number of tasks that the connector will run is set to 3 via the tasksMax setting. The replication.factor setting for replicated topics is 3. This means that the respective topic data will have three copies for each partition of the topic, and each copy will live on a different Kafka broker. For the offset-syncs topic, the replication.factor setting is 1, meaning that there are no copies of partitions in the offset-syncs topic. The sync.topic.acls.enabled settings is set to false, meaning that no ACLs are mirrored across clusters. The replication.policy.class setting configures how mirrored topics are named in the destination cluster. By default, mirrored topic names are prepended with the name of the destination cluster. However, the io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy setting ensures that the topic retains the original name of the topic. More information is available via the Strimzi documentation on cluster configurations.
The heartbeatConnector represents the configuration for the Kafka Connector that manages heartbeats. The heartbeats Kafka Connector emits heartbeat messages to the heartbeats topic, and allows for monitoring of the mirroring process between clusters.
The checkpointConnector represents the configuration for the Kafka Connector that manages the checkpoints. The checkpoints Kafka Connector consumes messages from the offset-syncs topic, and creates checkpoints for the mirroring process to allow MM2 to continue the mirroring process where it left off in the event of a failure. In the example above, the checkpointConnector has the following properties:
spec:
...
mirrors:
- ...
checkpointConnector:
config:
checkpoints.topic.replication.factor: 3
sync.group.offsets.enabled: true
refresh.groups.interval.seconds: 60
...
For the above configuration, the replication factor for the checkpoints topic is 3. This means that there are three copies of each partition in the checkpoints topic, and each copy lives on a different broker. The sync.group.offsets.enabled setting is set to true, meaning that consumer group offsets are mirrored from the source cluster to the destination cluster.
Finally, the topicsPattern and groupsPattern specify which topics and consumer groups are mirrored, respectively. Both of these parameters take a regex pattern. The .* value specified for both of these parameters means that all topics and all consumer groups are mirrored from the source cluster to the destination cluster.
Let's visualize the MirrorMaker2 configuration
Let's start with the Kafka Connector for the source cluster.
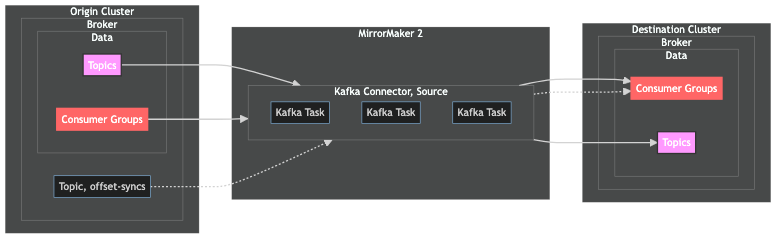
Above, we see the Kafka Connector for the source cluster and the data flows associated with it. The connector for the source cluster has 2 main responsibilities:
replicate topics and consumer group data from the source cluster to the destination cluster
produce consumer group offset mappings to the
offset-syncstopic
MM2 leverages the offset-syncs topic so that the connector tasks can pick up where they left off in the event of a failure or a restart. In the diagram above, the dotted line represents MM2 keeping track of the consumer group offset mapping so that it can keep the consumer groups in sync across both the origin and destination clusters.
Let's take a look at the Kafka Connector for heartbeats:
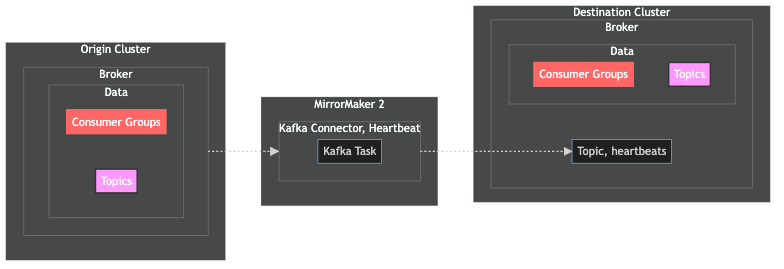
The connector for heartbeats has 1 primary responsibility:
produces a message from the origin cluster to the
heartbeatstopic on a specified interval (default is 1 second) to indicate liveness
The heartbeats connector is intended for monitoring purposes to indicate that both the source and destination clusters are available and healthy. If there's no "heartbeat", then MirrorMaker2 takes that as a signal to interrupt the replication process.
Finally, there's the Kafka Connector for checkpoints:
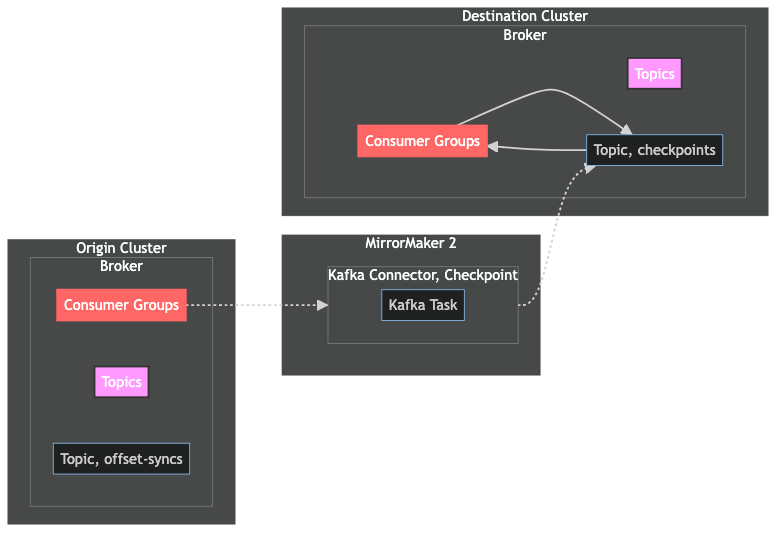
The connector for checkpoints has one primary responsibility:
produces messages containing consumer group offsets on the origin cluster to the
checkpointstopic on the destination cluster
MM2 uses the checkpoints topic to keep consumer groups that have been replicated to the destination cluster up to date. MM2 will periodically check the checkpoints topic, compare the messages in the topic to the specified offsets for the respective consumer group, and will update the consumer group offset if necessary.
Migration Gotchas
MM2 does an exceptional job of simplifying migrations between Kafka clusters, but there are two gotchas to account for and keep in mind.
Offset Translation. MM2 by default does a great job with offset translation in cases where Kafka topics have a retention period defined. However, if there are consumer applications that store offsets in a database, then those applications will need to account for the change in offsets.
Let's illustrate this with an example. Let's say that topic animals has 1,000 messages on the topic, and the latest offset is equal to 1,000. The retention period, defined via retention.ms, is set to 604,800,000 ms, which is the equivalent of 1 week. Of the 1,000 messages, let's say that 250 of those were created within the last week. So that means that 250 messages are still retained on the topic, and 750 messages have been cleaned up due to the topic retention policy. This means that when initiate the migration, only 250 messages for topic animals will get replicated from the origin cluster to the destination cluster, and the latest offset for the respective consumer group will be 1000 on the origin cluster and 250 on the destination cluster.
Size of Consumer Groups / Topics. Be mindful of how many consumer groups and topics there are on the source cluster. If there's a significant number of consumer groups, you may need to adjust the number of tasks running on behalf of the source connector. Monitor the replication status during the migration, and adjust the number of tasks via the tasks parameter accordingly.
Schema Registry Topic Schemas. When working with topics that leverage a schema, make sure that the destination cluster is working with the same schema definitions that the source cluster is utilizing. Schemas leverage something called a "magic byte", which is a unique identifier that a schema uses when serializing / deserializing messages. For example, with Confluent Schema Registry, I was bitten by the "magic byte" during the migration. The "magic byte" is a unique identifier that is randomly generated during the creation of a schema, and is unique per schema. It's not enough to recreate the schemas and utilize them with the new cluster, even if the schemas have the same schema IDs as the origin cluster. This is because while the schema IDs might match, the magic bytes won't have the same values. Fortunately, Confluent allows for exporting schemas across schema registries, which preserves the <magic_byte><schema_id><schema_bytes> format for each schema.
Fine-tune with Minikube. I can't emphasize this one enough. MM2 is a wonderful technology, but it does take some time to get used to and understand, especially if you haven't worked with Kafka much. For example, I built out a POC at irmiller22/mirrormaker2-poc with Minikube to better understand Strimzi Operator, MM2 configuration, and the data replication flow between clusters.
Closing Thoughts
The Strimzi team has done an exceptional job building out their Kafka operator for Kubernetes, and has one of the more in-depth documentation resources that I've seen out there for open-source technology.
Even though I used Strimzi Kafka operator explicitly for the MM2 functionality, I'll consider using the operator for projects where a managed solution is prohibitively expensive.
Please reach out at ian@ltce.dev or leave a message in the comments if there's more that you'd like to learn about MM2 or other topics. Thanks for reading!