

Shifting Left
Trends that have defined my last decade of Software Development

Software engineering has undergone a massive transformation since I started my career in 2013. When I first started, companies were shifting from on-premise to cloud-based software, and rearchitected their software to take advantage of the new cloud paradigm. These days, I’m witnessing the rise of a new industry-shifting technology - Artificial Intelligence (AI). It’s safe to say that a lot has changed in the last 12 years. I’m taking stock of the major trends that I’ve witnessed so far during my career, and sharing my thoughts in today’s post.
There are 4 trends that have contributed to the transformation in the enterprise software industry, and have impacted how engineering organizations approach the software development life cycle (SDLC). From monoliths to micro-services, Kubernetes, and the rise of Site Reliability Engineering (SRE) to AI-assisted development, these trends have set the stage for shifting critical functions — and the ownership of those functions — to the left.
Before I dive in, I’d like to share my background. I started my software career in 2013 as a backend engineer after completing a bootcamp at Flatiron School. I spent several years at Percolate, where I witnessed the rise of micro-services and Kubernetes firsthand, and followed the team through its acquisition by Seismic in 2019. Today, I’m part of Seismic’s SRE team, where one of my responsibilities has been evaluating AI-assisted development tools and rolling them out across the engineering organization.
Monoliths to Micro-services
The shift from monoliths to micro-services is largely a by-product of the rise of cloud computing. Monolithic architectures provide distinct advantages over micro-services if the following bullet points describe your organization:
Small engineering team / engineering organizations
Simple applications without complex logic / no need for breaking out specialized domains to meet scaling needs
Focus on product-market fit over revenue generation
I’ve had a hand in several monolith-to-micro-service transition projects. While there were different reasons used to justify each of the projects, scaling was a common thread. Performance scaling is a major driver, driven by the rise of cloud computing and a corresponding decrease in compute costs. This driver allows engineering teams to have full control of horizontal and vertical scaling isolated to a specific domain.
For example, I worked on a Django monolith application, and during the course of trying to achieve product-market fit (PMF), the domain logic for managing content had become bloated. This meant that were no clearly defined boundaries between the content domain and other domains in the monolith application, and resulted in performance implications that ultimately impacted customers. When a monolith starts to encounter scaling challenges and low-cost optimization solutions have been exhausted, spinning out the problematic domain with scaling challenges into a micro-service becomes a realistic option.
Organizational scaling is another driver. As an organization starts to scale beyond an extent where there is more collision of development changes in a monolith application code base, the organization typically will break up the engineering group into multiple teams where each team oversees a particular domain. This allows for teams to have more autonomy and oversight of their domain from a code management perspective.
The diagram below illustrates the main differences between monoliths and micro-services, and how they ultimately shape an engineering organization. The bottom half illustrates how this architectural shift mirrors organizational structure — a startup with 5-20 people sharing a monolithic codebase versus an enterprise with dedicated teams owning their own domains.

The diagram informs us of several key insights into organizational structure, and how they manifest downstream.
Monoliths have characteristics that are more favorable for startups:
Tight coupling of business logic, data access layer, and database(s)
Engineering teams “share” the monolith application domains
Supporting infrastructure (CICD, observability, etc) coalesced around monolith
Fast feature development that requires less cross-functional coordination
Enterprises, on the other hand, benefit from micro-services:
Loose coupling of business logic, data access layer, and database(s)
Engineering teams oversee their own application domains
Supporting infrastructure has to scale to support increasing complexity of services
Slower feature development that requires cross-functional coordination
Note that these are just a few of the many differences between monoliths and micro-services. An organization’s structure ultimately informs the path that the organization will take in the monolith-to-micro-service journey, and that has absolutely been true in my case. As organizations scale their teams and transition their services from monoliths to micro-services, critical functions such as service compute scaling, unit testing, and optimization of business logic within a domain get shifted left to a team that directly oversees that domain.
Kubernetes
Kubernetes (K8s) is the technology trend that has had the most significant impact on my career over the last 12 years. There was a Cloud Native Computing Foundation (CNCF) survey that said “96% of organizations [surveyed] are either using or evaluating Kubernetes”. The survey data is broken down below:
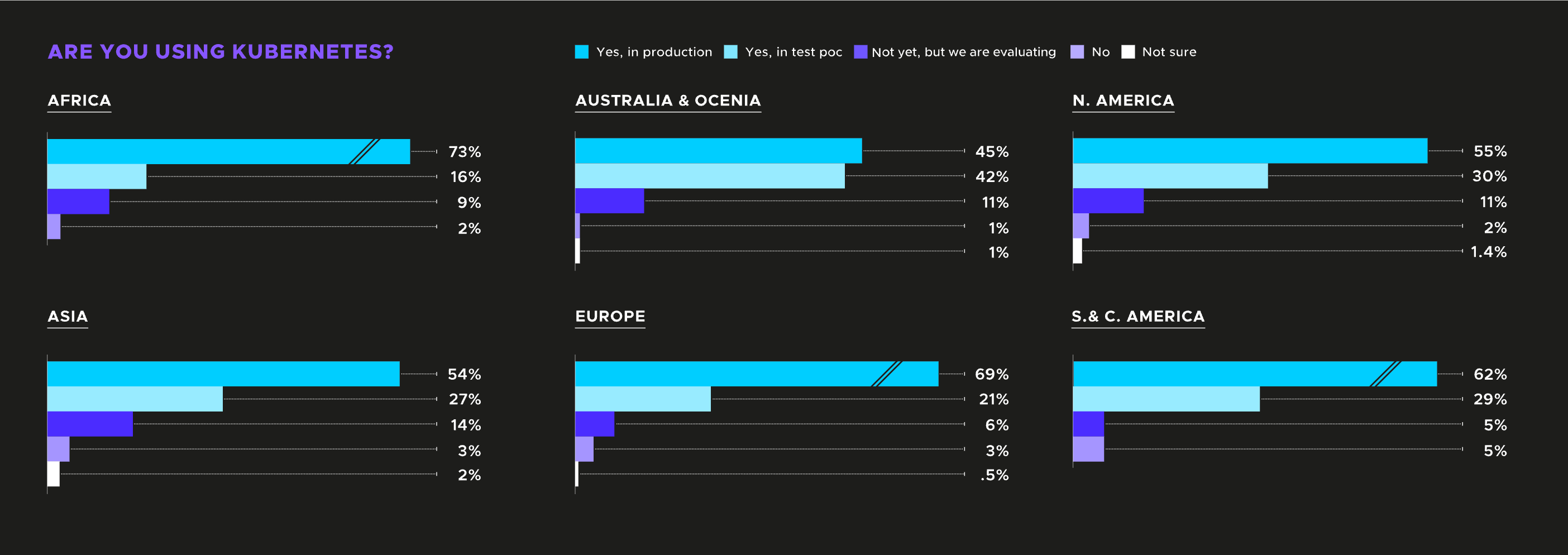
K8s introduced an orchestration layer that provided engineering organizations with 3 key benefits:
Resource management
Operational efficiency
Engineering productivity
K8s’ killer feature is a “scheduling” mechanism that promoted more efficient use of compute resources. The feature allows an engineering team to coordinate the deployment of services in such a way that the team’s services only utilize what they need by specifying the resources that they need at startup (“requests”) and the maximum that they can scale up to (“limits”). By configuring K8s features such as HorizontalPodAutoscaler resources or PodDisruptionBudget resources, engineering teams have a lot of capabilities they can leverage for resource management. In short, K8s makes up for its steep learning curve by providing a lot of features that are necessary for managing compute infrastructure in a cost-effective manner.
Operational efficiency has improved for engineering teams due to the leap in resource management capabilities that K8s introduced. The most significant impact has been in the resource optimization capabilities made possible by the K8s Metrics API. The Metrics API provides an endpoint for CPU and memory resource usage at both the pod level and the node level. This makes it quite powerful for teams to understand how services are utilizing resources, frees up teams from building out bespoke monitoring solutions, and allows teams to execute on strategic priorities such as cost optimization and efficient resource utilization.
That visibility also enables automation. K8s makes it possible to leverage the Metrics API and dynamically adjust resource allocations through scaling operations. For instance, if a service is experiencing 80% average CPU utilization across all of its pods, the HorizontalPodAutoscaler can automatically provision new pods to scale up the service and meet additional resource needs. This combination of observability and automated response is what makes K8s’ operational efficiency gains so durable — teams aren’t just seeing problems faster, they’re resolving them without manual intervention.
Engineering productivity has also skyrocketed for engineering teams that leverage K8s largely due to the ecosystem that K8s introduced. From ArgoCD to Harness and other GitOps-related tools for CICD pipelines, K8s has helped provide a platform for shifting what has historically been DevOps functions to the left. With enterprise organizations adopting K8s, there are 3 critical benefits:
ease of integration with CI/CD pipelines
faster time-to-market development time for new services
ability to provide multi-cloud strategies
Prior to the introduction of K8s, lots of different engineering organizations used a variety of tools or internally developed patterns for provisioning infrastructure and deploying services. From bespoke deployment scripting tools to other virtualization technologies like VMWare, the ecosystem for service orchestration was quite fragmented, and grew even more so as products started to transition from monolith services to micro-services. In my personal experience, K8s helped to shift left the management of resources at the service level from specialized DevOps teams to backend engineering teams.
Site Reliability Engineering
The Site Reliability Engineering (“SRE”) function is where I’ve also seen a significant amount of change, particularly as engineering organizations shift performance and reliability initiatives away from core engineering teams. This is largely thanks to Google’s influence on engineering organizations via Google SRE, which took traditional DevOps / operations teams, applied software approaches and best practices, and created the SRE discipline. The intent behind the SRE discipline was to bridge the gap between engineering development and operations teams, and it has since become a critical role within engineering teams. Full disclosure: SRE is also where my focus has been lately as part of the SRE team at Seismic.
SRE also has seen a profound impact on enterprise engineering organizations. In the DevOps Institute’s Global SRE Pulse 2022 report, 62% of organizations have adopted SRE in some shape or form. Within those organizations, 19% leveraged SRE across the entire organization, and 55% implemented SRE practices within specific teams, products, or services. Given that SRE is a relatively nascent discipline, this is a significant shift where engineering leaders see integrating SRE practices as a way to maintain competitive advantage.
At Seismic, the SRE team was built from scratch in response to scaling and reliability pain. As the platform grew — both organically and through several acquisitions — the operational burden on engineering teams became noticeable. There was no dedicated function focused on reliability as a discipline, and incidents were handled reactively rather than systematically. Standing up a dedicated SRE team was the answer to a question that had been building for a while: who owns reliability?
The answer, it turns out, is everyone — but SRE’s role is to make that ownership practical. At Seismic, we’ve shifted reliability left in three meaningful ways.
First, engineering teams now define and own their own Service Level Objectives (SLOs) and Service Level Indicators (SLIs). Rather than SRE dictating what “reliable” means for a given service, the team that builds and operates the service sets those targets based on their understanding of customer expectations. Error budgets provide a shared language for balancing reliability investment against feature velocity — when you’re burning through your error budget, reliability work takes priority; when you have budget to spare, you ship features with confidence.
Second, on-call ownership has shifted to the teams closest to the code. This was a cultural shift as much as an operational one. Engineers who build a service are best positioned to diagnose and resolve issues with it, and owning on-call creates a natural feedback loop — if your service pages you at 2 AM, you’re motivated to fix the underlying issue rather than apply a band-aid.
Third, we invested in self-service observability. SRE built out shared platforms and tooling that engineering teams use to instrument, monitor, and alert on their own services. Instead of filing a ticket with an ops team to get a dashboard, engineers have the autonomy to build the visibility they need. This democratization of observability has been one of the highest-leverage investments we’ve made — it gives teams the data they need to make informed reliability decisions without creating a bottleneck.
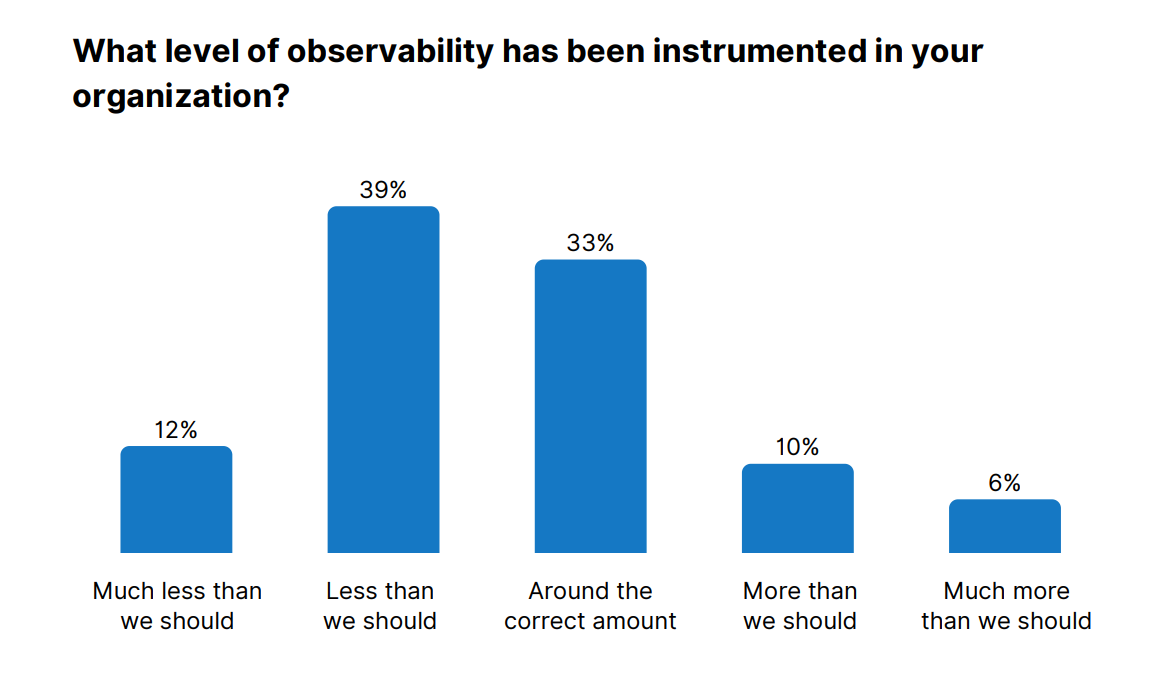
— Observability Gap
This investment was far from unique — according to the Catchpoint SRE Report 2025, over half of organizations still report not having enough observability.
The common thread across these three shifts is a move from centralized gatekeeping to distributed ownership, enabled by shared platforms and practices. SRE didn’t shift responsibility onto engineering teams and walk away — it shifted capability left by building the tooling, frameworks, and culture that make reliability a first-class concern for every team. That’s a fundamentally different model from traditional operations, and it’s one that scales with the organization rather than against it.
AI-Assisted Development
AI-assisted development is the most recent, and arguably the most disruptive, trend I’ve witnessed. As part of Seismic’s SRE team, one of my responsibilities has been evaluating AI development tools and identifying use cases where they can meaningfully improve engineering workflows.
We took a structured approach to the evaluation, looking at multiple tools including GitHub Copilot, Claude, and ChatGPT across different use cases. Two criteria rose to the top: workflow integration and measurable ROI. A tool that produces impressive demos but doesn’t fit into an engineer’s existing IDE, CI/CD pipeline, or review process won’t see sustained adoption. Similarly, engineering leadership needed to see concrete productivity gains, and not just anecdotal enthusiasm, to justify the investment.
The initial reception among engineers was skeptical. Many viewed AI code assistants as glorified autocomplete, and there were legitimate concerns about code quality, security implications, and whether these tools would generate more technical debt than they resolved. Winning people over required a mix of approaches: data-driven metrics for leadership, live demos of real workflows, and enabling a handful of early adopters whose results could speak for themselves. Attitudes shifted once engineers saw where AI genuinely helped rather than just impressed.
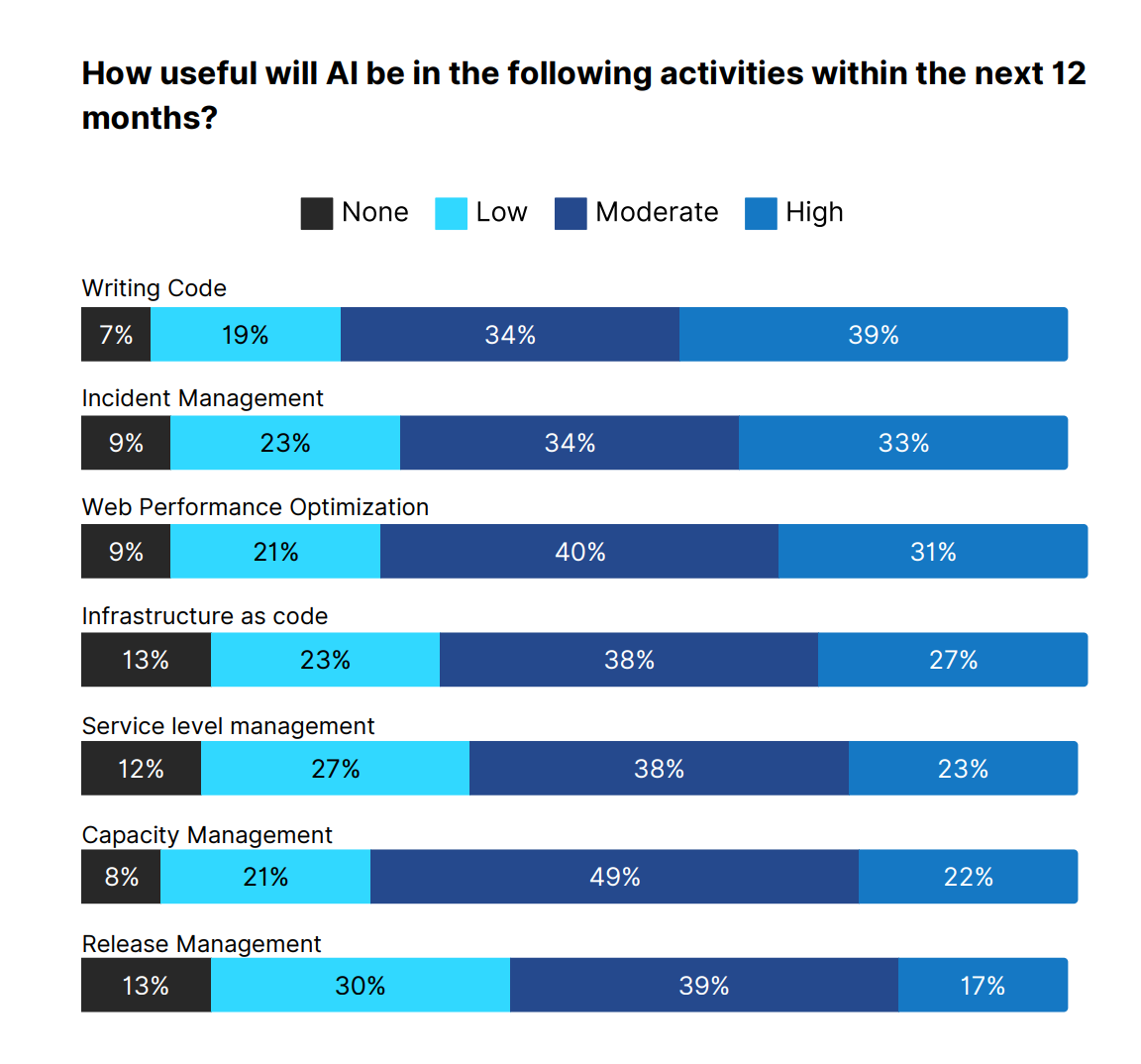
At the individual developer level, the impact has been most visible in four areas: generating boilerplate and scaffolding code that nobody wants to write by hand, navigating unfamiliar codebases where the AI provides context-aware suggestions faster than reading through documentation, generating unit tests and edge cases that improve coverage, and producing documentation and inline comments from existing code. None of these are flashy use cases, but that’s the point. The cumulative time saved on routine work compounds into meaningful productivity gains across an engineering organization. The chart below from Catchpoint illustrates the impact of various AI use cases.
Where things get more interesting, and more relevant to the “shifting left” theme of this post, is in applying AI to SRE-specific workflows. I’ve been experimenting with connecting AI tools to observability and incident management platforms through integration protocols like MCP (Model Context Protocol). To appreciate why this matters, consider what incident triage typically looks like without it: an engineer gets paged, then scrambles across four or five tools — the alerting platform, observability dashboards, log search, deployment history, and a runbook — context-switching between tabs and mentally correlating signals. How long it takes to form a hypothesis depends on the engineer’s familiarity with the service, the clarity of the alert, and sometimes just luck. MCP collapses that workflow: rather than an on-call engineer manually jumping between dashboards, log viewers, and run-book documentation during an incident, the AI can pull from those sources and help synthesize what’s happening. The biggest win so far has been in the first few minutes of an incident - the triage phase where identifying the blast radius and narrowing down the likely root cause has the highest leverage. Having an AI assistant that can query your observability platform, cross-reference recent deployments, and surface relevant historical incidents in a single conversation meaningfully compresses the time from “something is broken” to “here’s where we should look.”
Outside of work, I’ve been using Claude and Claude Code for personal projects, and the experience has shifted how I think about AI tools as an engineer. Claude has become more of an architectural thinking partner — something I use to talk through design decisions, debug tricky problems interactively, and explore unfamiliar technologies before committing to an approach. The distinction matters because it reveals that “AI-assisted development” isn’t a single capability — it’s a spectrum that ranges from autocomplete to autonomous agents, and different tools occupy different positions on that spectrum depending on the use case.
The “shifting left” dimension of AI-assisted development is perhaps the most profound of the four trends in this post. AI tools are compressing the feedback loop between writing code and understanding its implications for testing, security, performance, and documentation. Tasks that previously required specialized knowledge or a separate review cycle can increasingly happen in the moment, at the point of development. When an engineer gets real-time feedback on a potential security vulnerability or a performance anti-pattern as they write the code, that’s shifting left in its purest form. And when an on-call engineer can triage an incident in minutes instead of the time it used to take to manually correlate data across half a dozen tools, that’s shifting left applied to operations, which brings the entire arc of this post full circle.
Takeaways
Looking back at the last 12 years, these four forces collectively shifted software engineering from monolithic craftsmanship toward distributed, automated, reliability-engineered systems. Infrastructure became code. Services became composable units. Operations became a discipline. And artificial intelligence became a collaborator. The cumulative effect has been to fundamentally raise the ceiling of what small teams can build and operate at scale by shifting complex organizational functions to the left.
The practical lesson I’d share with engineers navigating these shifts is that each trend didn’t eliminate complexity, but rather redistributed it. Micro-services gave teams autonomy but introduced coordination overhead. Kubernetes gave teams power over their infrastructure but demanded a steep investment in learning. SRE gave teams ownership of reliability but required cultural change around on-call and error budgets. AI tools are giving teams speed and rapid iteration but demand new judgment about when to trust the output and when to question it.
The ones who thrive through these transitions aren’t the ones who master every new tool first. They’re the ones who understand why the shift is happening and adapt their mental models accordingly. “Shifting left” isn’t just about moving tasks earlier in the development lifecycle - it’s about moving ownership, capability, and accountability closer to the people who are best positioned to act upon them.